





![[新浪彩票]足彩22023期盈亏指数:曼城主胜做胆](https://tokyo-c-m.com/zb_users/upload/2024/02/202402121707710189731409.png)

世界杯火热开赛,谁是你心中的冠军队伍?快去为你支持的球队助威吧!2022.11.18-12.18 世界杯期间,参与球队助威,即有机会瓜分盐粒奖池。助威次数越多,助威球队每场获胜后瓜分赢取的盐粒越多。每日达成任务成就还可获得额外创作分奖励,加速获得助威次数。点击下方链接,马上去助威吧>>>为你支持的球队助威,赢知乎盐粒
一直就有个高大上的职业,叫精算师
大家以为一些比较受关注度的足球比赛的赔率是怎么定出来的呢?
没错,就是博彩公司雇佣的精算师算出来的
而且
精算师算出来的赔率
能保证博彩公司是 小赢,中赢,还是大赢
可能也偶尔有失手
不过绝大多数情况都是绝对靠谱的
可能就有人好奇了
精算师是怎么算出来的呢?
其实这看似玄幻的精算背后,基础数学原理主要有两个,“期望值”和“大数定律”
期望值,从某种意义上来说,是大家对一个未发生事件,依据其相关已知的事情,来猜测或者说预计出现的结果,知道的东西越多,越详细,越有用,那么你所能推测出来的结果越真实,越具体。
而精算师就是通过博彩公司提供的强大信息源,比如 球员真实状态,伤病,战意,心理因素等个人问题,以及球队状况,草皮,天气,球迷的数量等等客观因素,还有好多可能想都想不到的数据,来综合评定一场比赛的结果,准确率高的吓人!
大数定律就更简单了,事情发生的足够多了,总会往趋近期望值的方向发展!看似随机的事情,实际上有着某种必然出现。
现在你明白了吧:
A1:对于博彩公司来讲,靠谱,这只不过是把精算师换成AI罢了
A2:对于你来讲,不靠谱
你以为你和博彩公司差的是精算师吗
并不,你和博彩公司差的是那海量级的强大信息源
对于我们来讲,赌球只有小输,中输,和大输
如果你一定要玩的话
随便压个零花钱,小赌怡情即可
千万不要用你的“怡情”的小爱好,去妄图挑战别人赚钱的资本。
实话,AI预测的不一定比上面Code预测的准。
这几天刚好看过一个kaggle上的AI预测世界杯的项目,截至目前12场比赛对了8场,准确率67%
AI预测大致实现流程是这样的:
1、获取数据集作为训练input
数据集很大很全,包括:FIFA1992-2022年的国际足联世界排名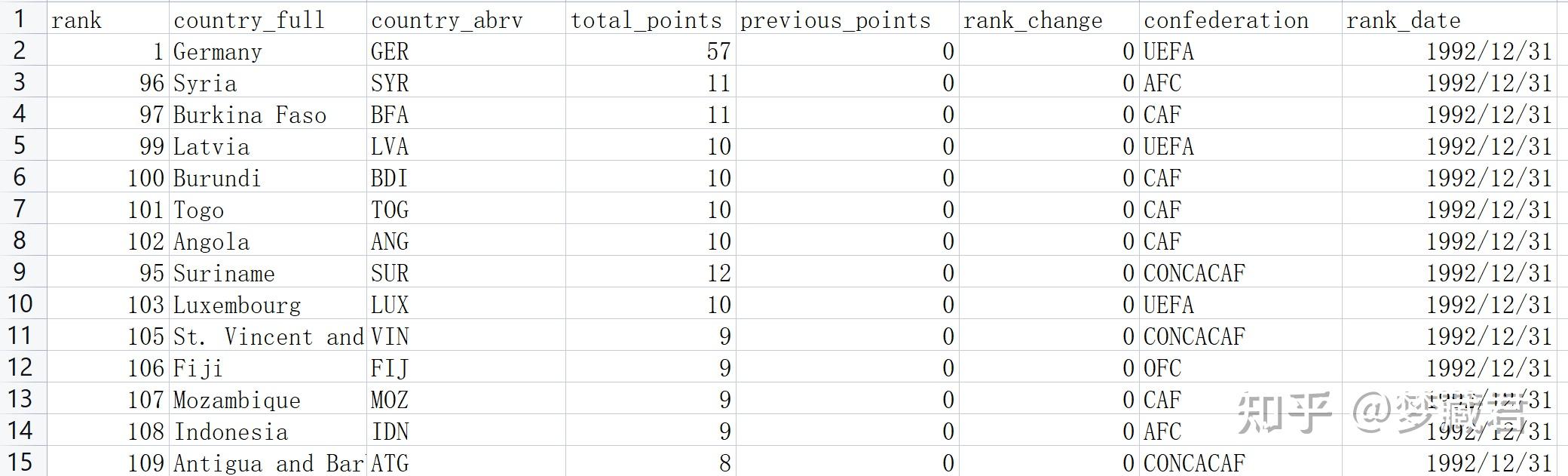 从网络上得到的1916-2022年的各个球队/球员的进球、射门、比分结果数据
从网络上得到的1916-2022年的各个球队/球员的进球、射门、比分结果数据
注意:实际上早些年的数据可能参考意义没那么大,所以实际运行项目的时候大概只取了最近4年左右的数据
2、特征工程
特征工程就是把原始数据转变成描述进球相关参数特征的过程,相当于人工去设计输入变量X
这里仅靠程序知识是不够的,还得特别懂球才行,这个项目的特征大概有这么些考虑维度:平均进球数最近5场比赛平均进球数平均犯规数最近5场比赛平均犯规数FIFA平均排名最近5场比赛FIFA平均排名FIFA积分最近5场比赛FIFA积分比赛得分最近5场比赛得分
最终生成特征
3、建模与训练
应该是试了几种模型,最后选择了GradientBoosting作为预测模型,这里有一个关键指标AUCAUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值
这个模型的AUC≥0.75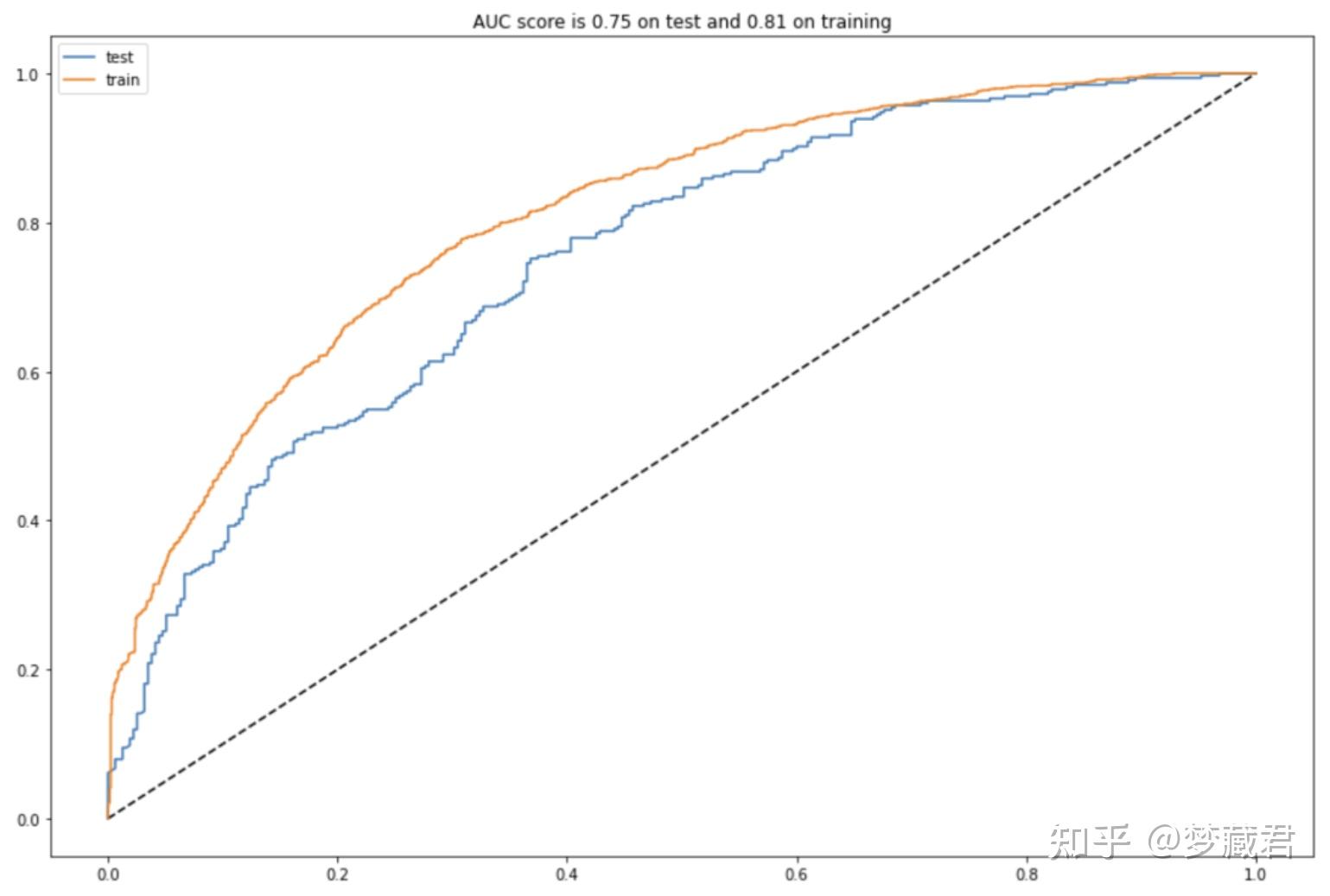
4、预测
小组赛已经全部预测,从实际结果来看,目前12场预测准确8场,准确率67%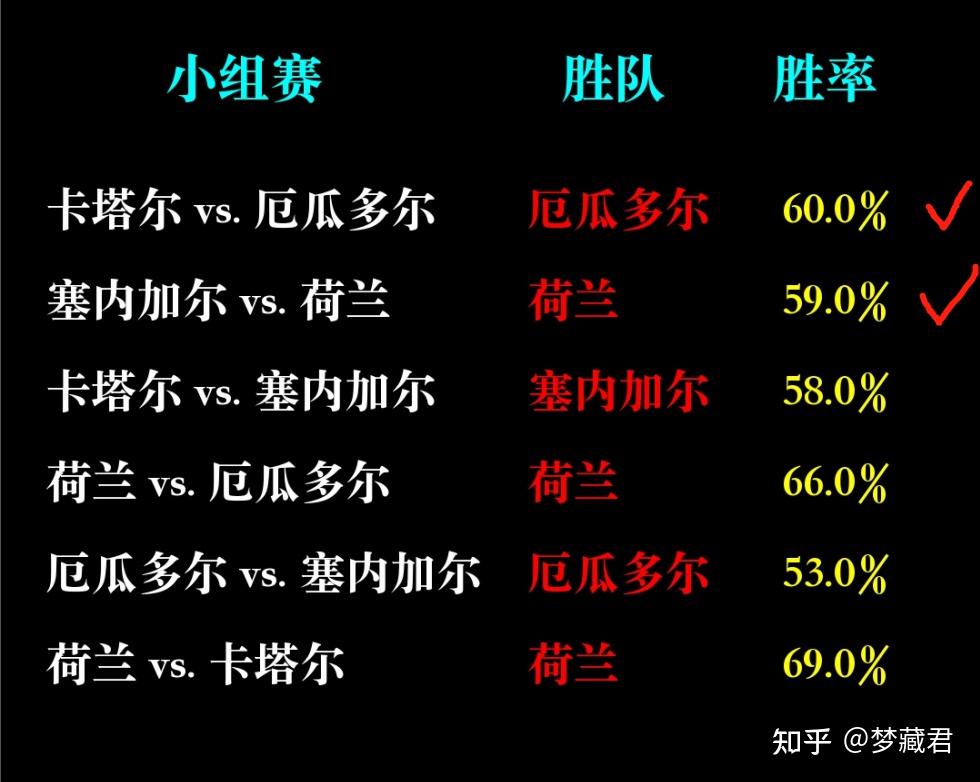
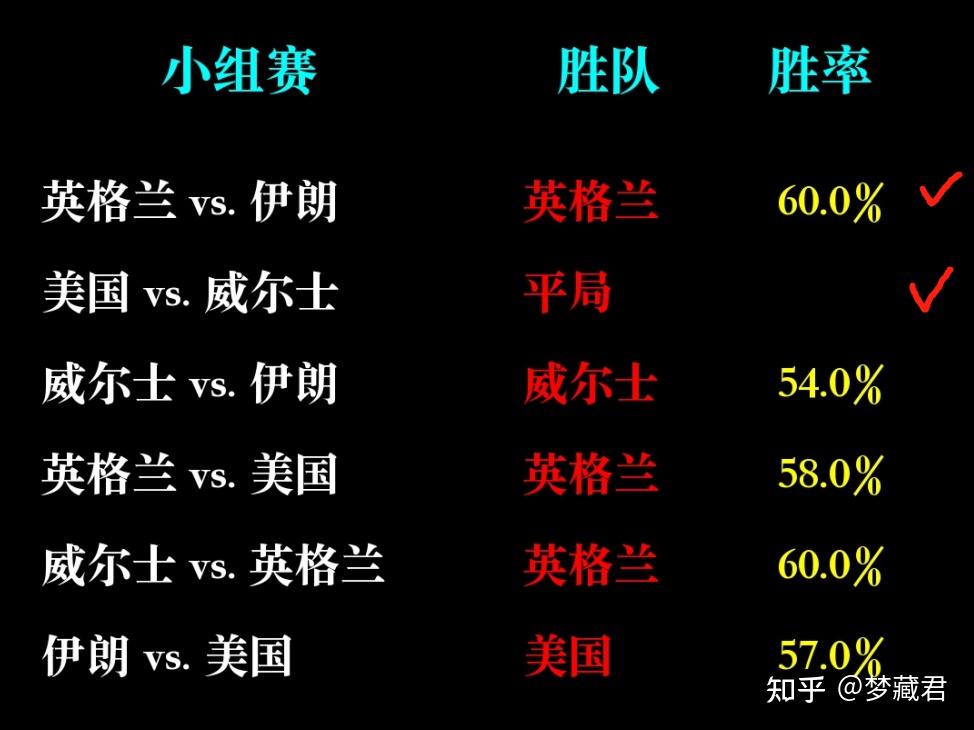
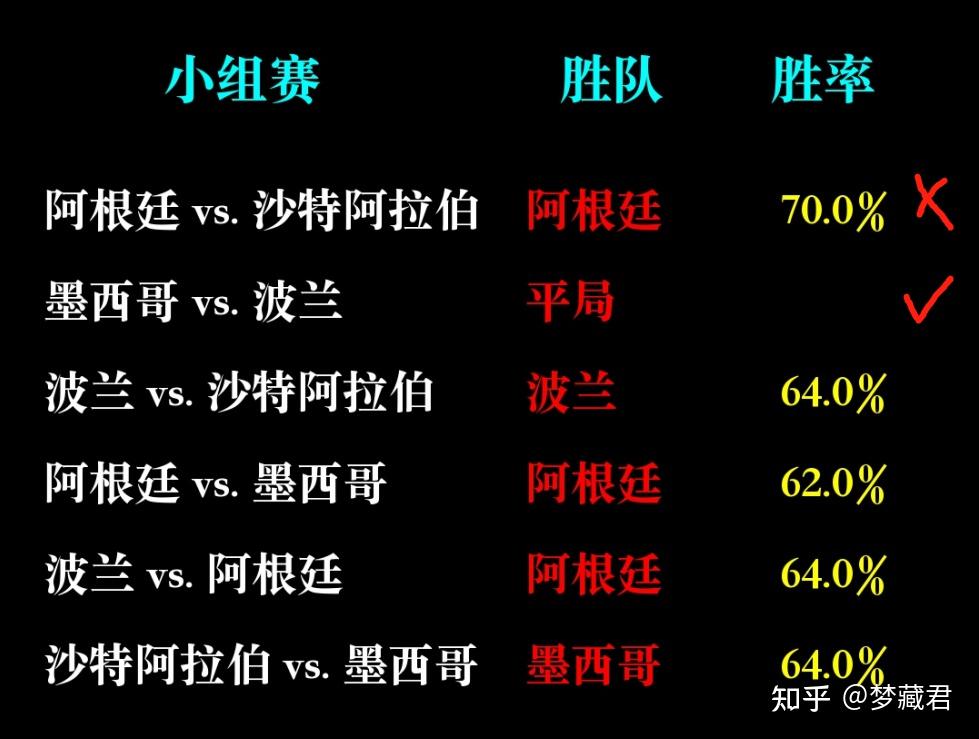
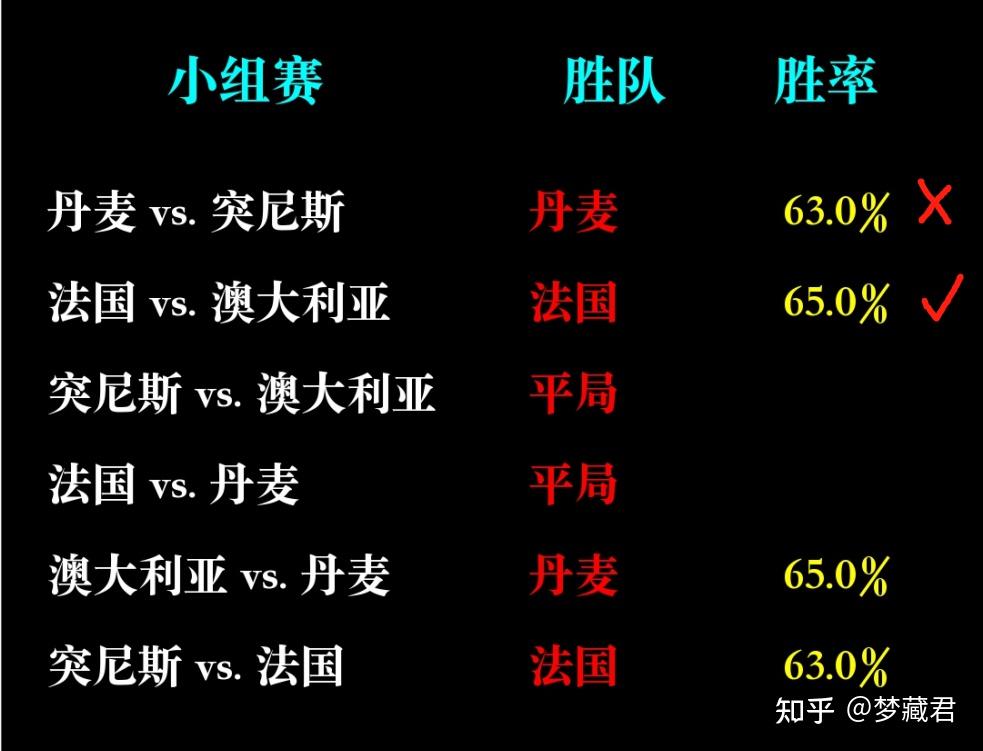
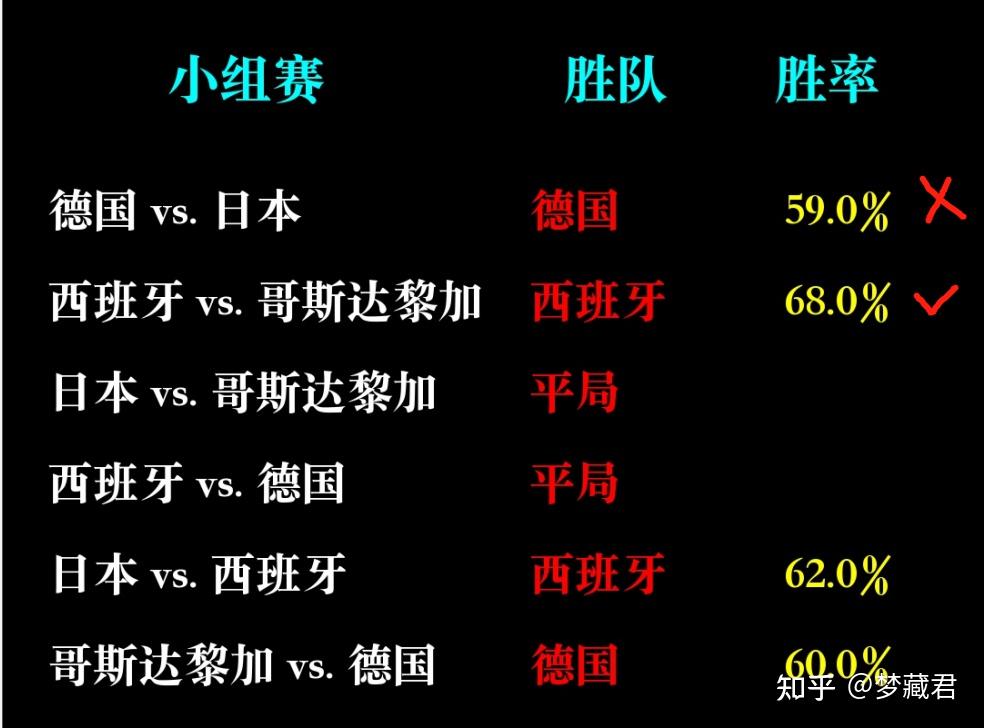
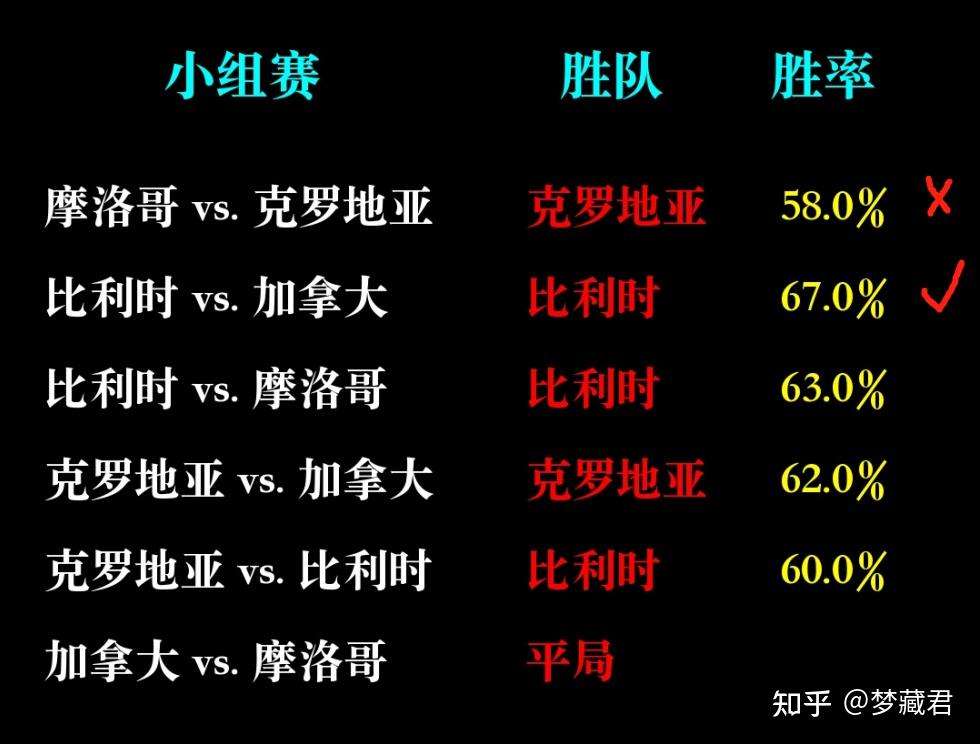
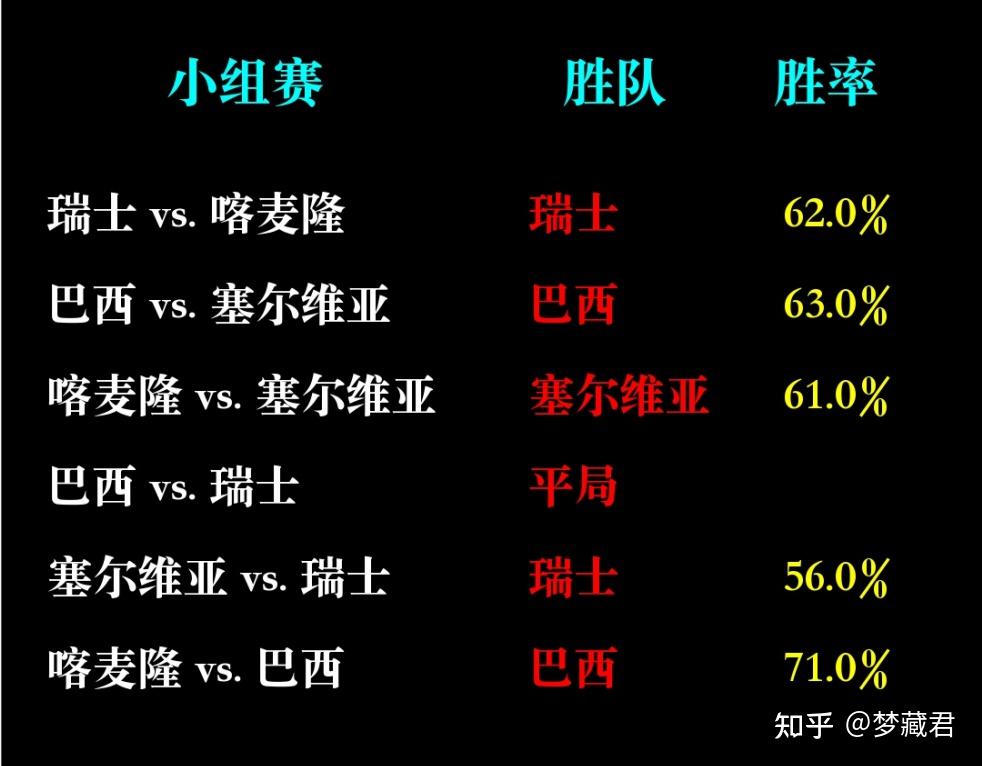
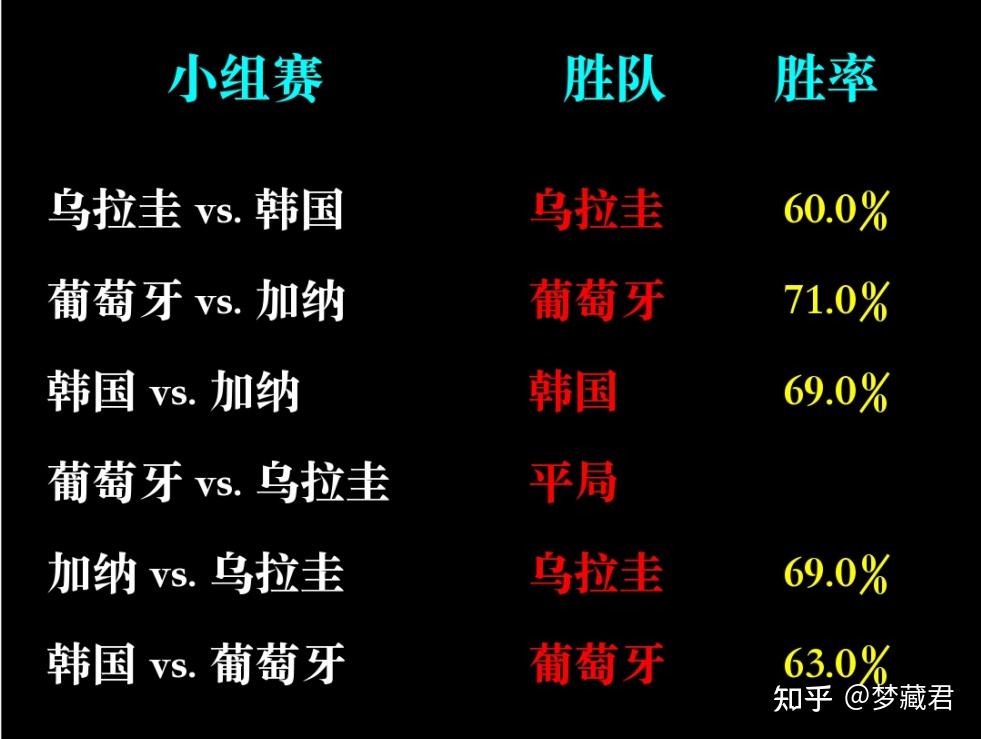
任何预测的准确率都不可能100%,除非是从未来穿越回来的,AI也只是基于过去数据预测一种可能性,以及这种可能性发生的概率
毕竟,现实比赛的天气环境、球员士气、实时场地、轻视对手、强行装逼等等非常重要的因素,AI可是都没法考虑进去呢
不靠谱,不管使用的模型有多好,足球都是一项相当随机的游戏,这也是它的魅力。
至于如何操作,可以参考艾伦·图灵研究所创建的一个预测今年世界杯结果的AI模型——AIrsenal[1](改良版)。Alsenal是研究所的工作人员在2018年为了玩儿梦幻英超(FLP)开发的,Alsenal本身是在Dixon和Coles(足球预测界的经典)的基础上开发的,该模型包含球队进攻强度、防守强度和主场优势的参数,并使用贝叶斯统计来计算比赛最有可能的比分。
研究人员对Alrsenal的修改主要是为了使它更适合预测国际结果。例如,国际球队最常与来自同一大洲的球队比赛,这可能会在试图预测来自不同大洲的球队之间的结果时产生偏差。为了解决这个问题,研究人员引入了不同大洲联合会相对优势的模型参数。此外,模型还考虑了主场优势不适用于国际锦标赛的事实,除非主办国在比赛。
研究者使用了GitHub用户martj42编制的自1872年以来每场国际足球比赛的综合数据库,经过实验后,最终使用了从2002年世界杯开始的所有国际结果。
在训练数据中给予世界杯比赛最重要的权重(降低大陆锦标赛、资格赛和友谊赛的权重),也给了最近的比赛更多的权重。另外还将国际足联的官方排名输入了模型,以提供对球队表现的最新估计。
而球员阵容、判罚情况、地点和天气等数据由于难以收集或建模而没有被使用。
最后的预测结果是:巴西获胜的机会最大(25%),其次是:比利时、阿根廷和法国[2]。图片来源于艾伦图灵研究所官网
英格兰只有7%的机会获胜,不到60%的机会进入四分之一决赛或更远。
AI已经给出了它的预测结果,但是在阿根廷1-2不敌沙特,德国1-2不敌日本的冷门后,你还相信它吗?
最后,心疼一下内马尔。 图片来源于网络
图片来源于网络
传播先进文化、推动社会进步,蒙您欢喜,不要忘记点赞、分享、关注@清华大学出版社 IT专栏
哦~
我们学校有一个老师专门在做这个事情:用AI预测足球比赛的结果。从前深度学习时代做到现在,也算是从一而终了。 这老师的Google Scholar首页
这老师的Google Scholar首页
对这个任务,有专门的数据集,有专门的模型,也有专门的比赛: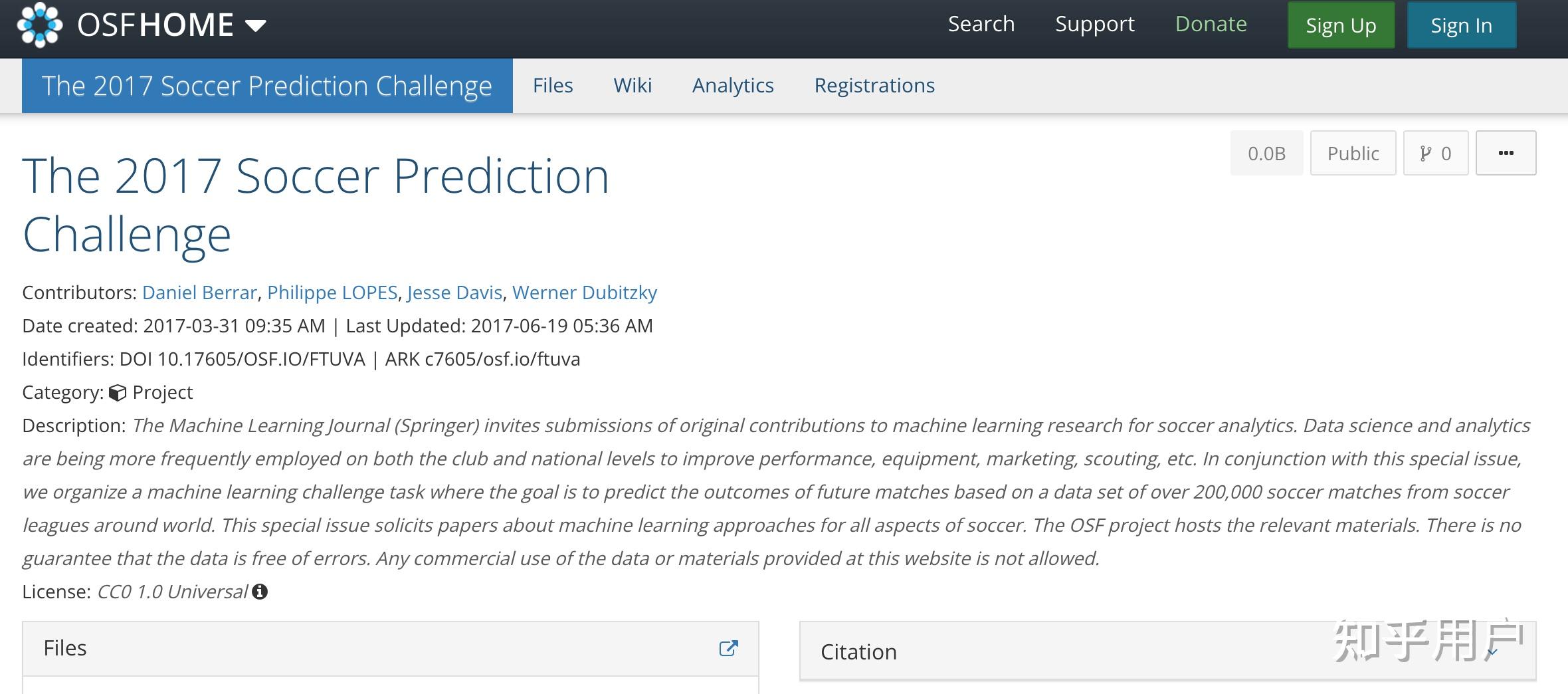
总的来说,这个世界上确实有那么一拨人在努力解决这个问题。由于这个领域实在是缺乏大量的数据,一些先前的研究仍然与统计高度相关。一些出现过的方法可以被分类为:统计模型:有序的probit回归模型(Kuypers 2000;Goddard和Asimakopoulos 2004;Forrest等人2005;Goddard 2005)和泊松模型(Maher 1982;Dixon和Coles 1997;Lee 1997;Karlis和Ntzoufras 2003;Angelini和 Angelis 2017)。Joseph、Fenton和Neil(2006)[1]研究的重点是建立一个专家贝叶斯网络来预测托特纳姆热刺队在1995-1997年期间的成绩。他们证明了他们的专家贝叶斯网络优于其他机器学习技术,如K-近邻、朴素贝叶斯和MC4决策树。Owramipur、Eskandarian和Mozneb(2013)[2]提出了一个贝叶斯网络,用于预测西班牙足球队巴塞罗那队的足球成绩。他们的研究展示了有趣特征的使用,如天气状况、球员的心理状态以及是否有主要球员受伤。他们报告了非常高的准确率,平均准确率为92%,但他们的系统只为一支球队和一个赛季建模,只涉及被观察的球队的20场比赛。Constantinou和Fenton(2013)[3]根据他们之前的研究(Constantinou, Fenton, & Neil, 2012)[4],提出了另一个用于预测协会足球比赛结果的贝叶斯网络。他们用自己的模型预测了2011-2012赛季英超的每场比赛,并在每场比赛前在网上公布了他们的预测结果。他们证明了他们能够通过使用比以前的研究不那么复杂的模型来产生盈利的回报。Dixon和Coles(1997)[5]对每支球队的进球数采用了双变量泊松分布,并以与球队过去表现有关的特征为参数。然而,他们的重点是将开发的模型作为制定博彩策略的基础,使其产生超过博彩公司赔率的正预期收益。Goddard(2005)[6]使用了一个有序的probit回归模型来预测一场足球比赛的结果。他们的研究涉及到各种有趣的预测因素,如球队主场的地理距离和比赛的平均上座率,他们能够证明这些解释变量对预测比赛有意义。然而,他们的研究广泛地集中在对经济收益和固定赔率博彩市场的价格效率的分析上,而不是对比赛的预测。Karlis和Ntzoufras(2010)[7]将加权似然法与传统的最大似然法进行了比较,结果显示他们提出的方法对离群值提供了有效的保护。Boshnakov, Kharrat, and McHale (2017)[8]介绍了一个模型,该模型使用基于Weibull间隔时间和copula的计数过程来产生一场比赛中主客队进球数的双变量分布。机器学习和概率图模型:遗传算法(Tsakonas等人,2002;Rotshtein等人,2005),贝叶斯或马尔科夫方法(Joseph等人,2006;Baio和Blangiardo,2010;Rue和Salvesen,2010;Constantinou等人,2012,2013)以及神经网络(Cheng等人,2003;Huang和Chang,2010;Arabzad等人,2014)Rotshtein、Posner和Rakityanskaya(2005)[9]创建了一个用于足球预测的模糊模型,其中的参数是使用遗传算法和神经网络的组合进行调整。他们将这个模型应用于芬兰锦标赛的比赛数据,并表明这些用于模型参数选择的调整技术改善了他们的模糊逻辑模型的结果。Godin、Zuallaert、Vandersmissen、De Neve和Van de Walle(2014)[10]以及Schumaker、Jarmoszko和Labedz(2016)[11]利用了社会媒体平台的集体知识,特别是Twitter。Schumaker等人(2016年)利用他们收集的推文中的情绪来预测比赛结果,以及做出有关赌注的决定。他们表明,众包产生的结果比使用领域专家更好,特别是在赌注决策方面。Godin等人(2014年)使用集体知识和传统统计学习技术的混合方法解决了这个问题。然而,他们的工作更注重于提高博彩公司的预测赔率,以实现更大的货币利润。评分系统:基于广为人知的ELO评级系统的变种(Elo 1978;Leitner等人,2010;Hvattum和Arntzen,2010)等。ELO评级最初由Elo(1978年)[12]提出,用于国际象棋选手的排名,但后来被Hvattum和Arntzen(2010年)[13]改编为足球比赛预测问题,他们使用经济和统计措施来比较应用于足球比赛预测的ELO排名系统与一组六种基准预测方法的优点。Constantinou、Fenton和Neil(2013)[14]随后提出了另一种评级技术,称为pi-rating,该技术被证明优于Hvattum和Arntzen(2010)提出的ELO调整。
显然这类问题就像是做量化一样,对特征的构建几乎决定了对结果的预测是否准确(Joseph等人,2006年[15],Owramipur等人,2013年[16])。我们知道量化分析的预测会分析时序上的信息、该时刻大盘横截面信息,设计各种因子,甚至考虑一些外部舆论信息。
大多数现有研究也尽可能在多方面考虑各种特征。主/客场因素,几乎是必选特征。各队的进攻、中场、防守和整体评级。进球数量差距。在建立足球预测模型时,进球数差是非常重要的。Constantinou和Fenton(2013)引入的pi评级系统提供了经验证明,进球数差作为预测足球比赛结果的一个特征,效果很好。
不同研究选择的特征侧重是不一样的,例如在一篇研究中,作者选择使用角球、射门和进球作为衡量球队表现的最重要指标。时间维度上的球队近期表现,并根据每场比赛进行系数更新。
之后就是根据特征进行的建模了。在这类预测任务上,一些非NN方法如GBDT的表现个人认为比神经网络方法稳健得多。
实际上,不止足球比赛,类似的团队竞赛如排球和篮球都有一些研究出现。一个相关的综述可以看这里:
Baboota, Rahul, and Harleen Kaur. "Predictive analysis and modelling football results using machine learning approach for English Premier League."International Journal of Forecasting35.2 (2019): 741-755. The Application of Machine Learning Techniques for Predicting Results in Team Sport: A Review


















留言0